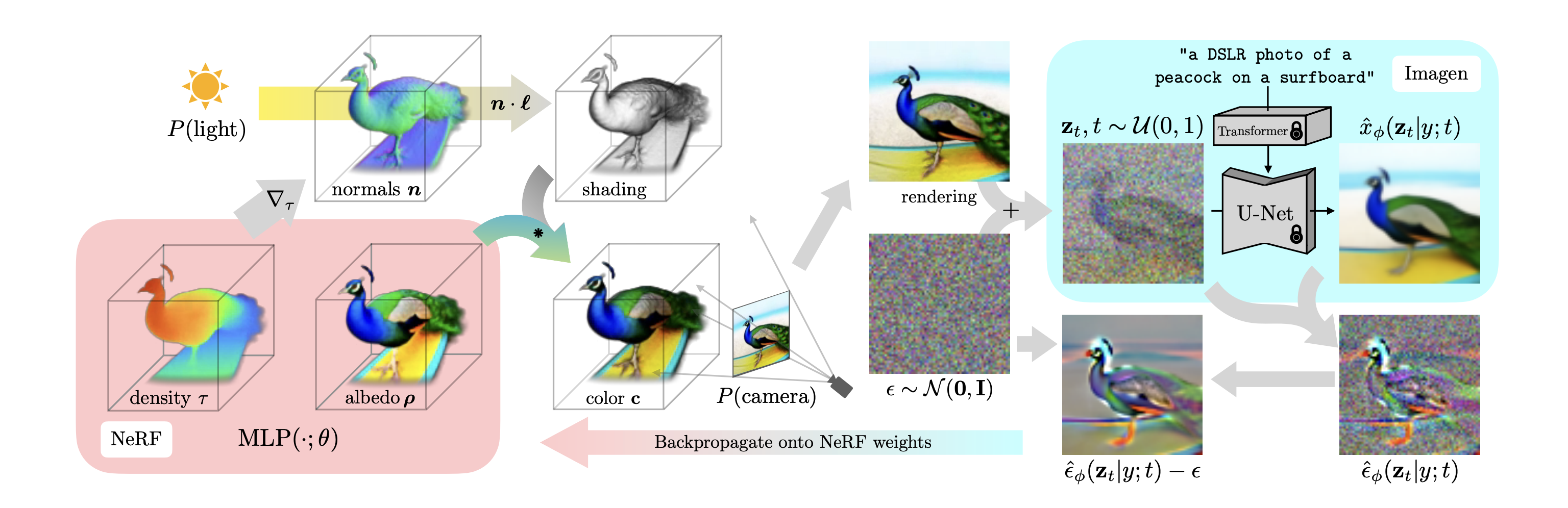
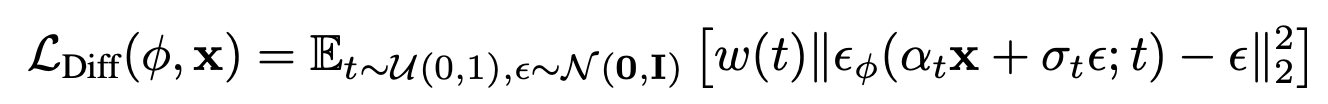文本到图像合成的最新突破是由在数十亿个图像-文本对上训练的扩散模型推动的。
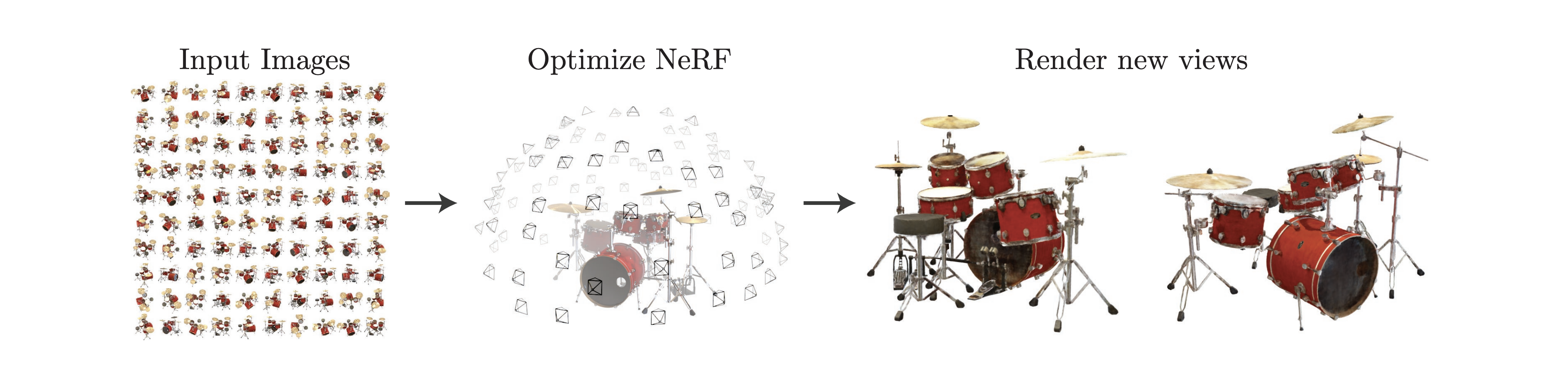
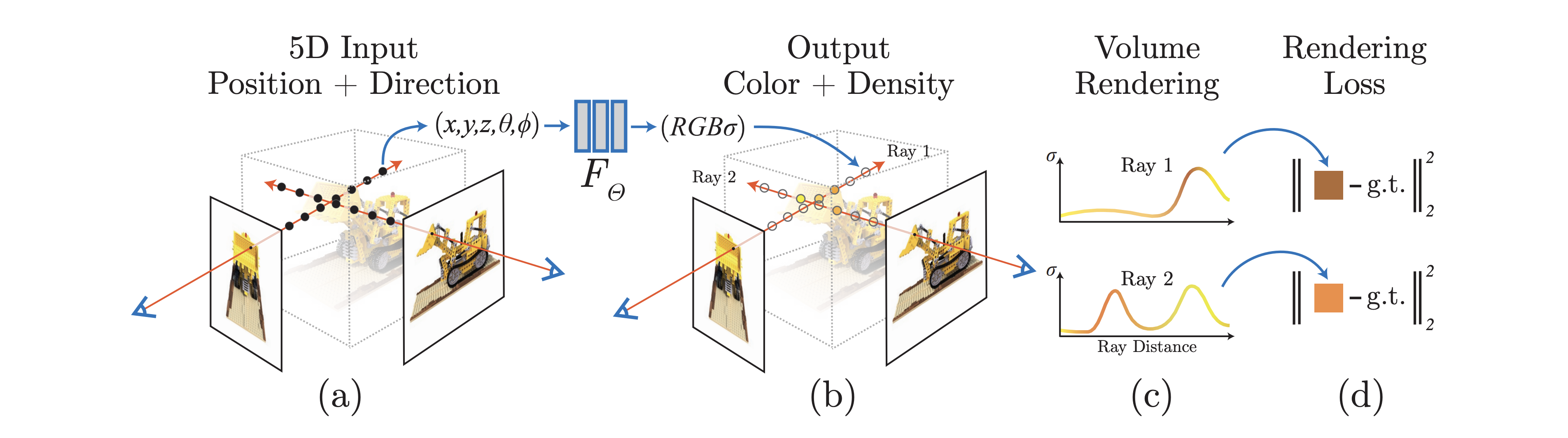
将这种方法应用于 3D 合成需要大规模的标记 3D 资产数据集和用于对 3D 数据进行去噪的有效架构,
而这两者目前都不存在。在这项工作中,作者通过使用预训练的 2D 文本到图像扩散模型来执行文本到 3D 合成,从而规避了这些限制。
作者引入了基于概率密度蒸馏的损失,使得可以使用 2D 扩散模型作为优化参数图像生成器的先验。
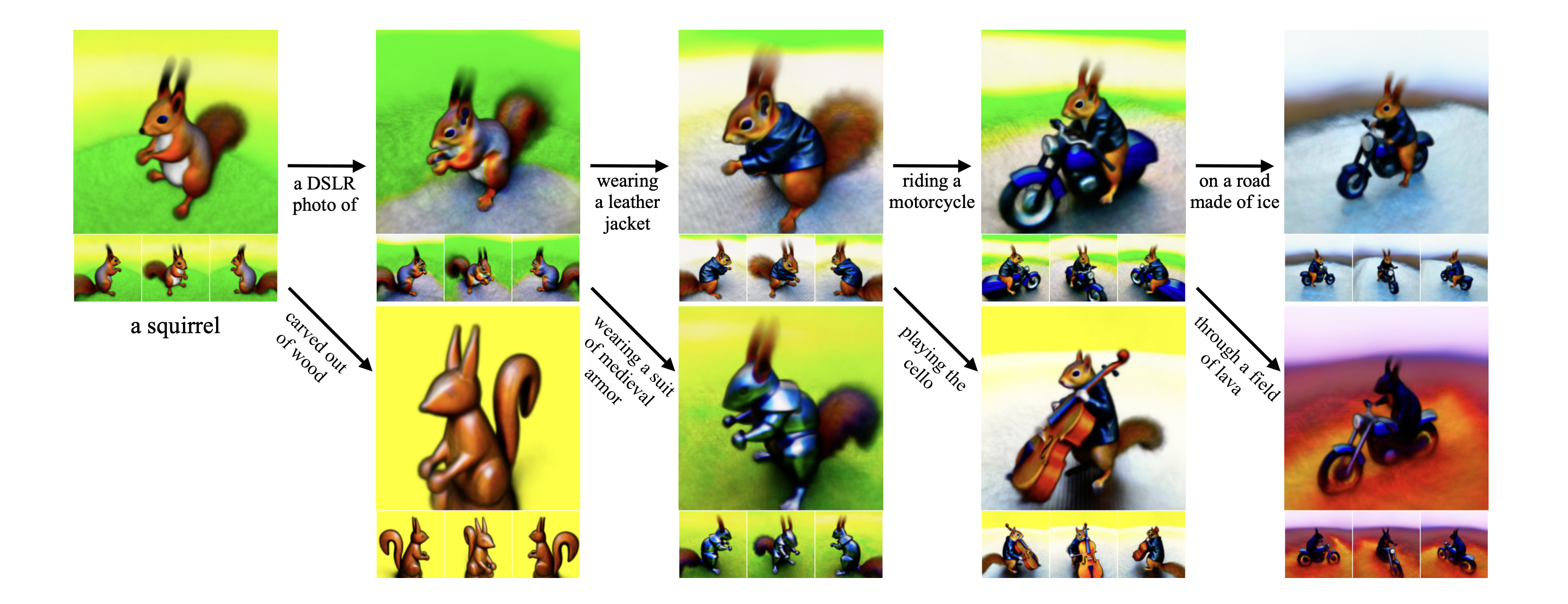
在类似 DeepDream 的过程中使用此损失,作者通过梯度下降优化随机初始化的 3D 模型(神经辐射场,或 NeRF),
使其从随机角度进行的 2D 渲染实现低损失。给定文本的最终 3D 模型可以从任何角度查看,通过任意照明重新点亮,或合成到任何 3D 环境中。
作者的方法不需要 3D 训练数据,也不需要修改图像扩散模型,证明了预训练图像扩散模型作为先验的有效性。